-
Erlang explained: Selective receive
If you worked with Erlang you’ve probably heard about selective receive. In this article I want to demonstrate what selective receive is and how it works. Let me start with an excerpt from Joe Armstrong’s book Programming Erlang (Section 8.6, p.155):
receivePattern1 [when Guard1] -> Expressions1;Pattern2 [when Guard2] -> Expressions2;...afterTime -> ExpressionTimeoutend- When we enter a receive statement, we start a timer (but only if an after section is present in the expression).
- Take the first message in the mailbox and try to match it against
Pattern1,Pattern2, and so on. If the match succeeds, the message is removed from the mailbox, and the expressions following the pattern are evaluated. - If none of the patterns in the receive statement matches the first message in the mailbox, then the first message is removed from the mailbox and put into a “save queue.” The second message in the mailbox is then tried. This procedure is repeated until a matching message is found or until all the messages in the mailbox have been examined.
- If none of the messages in the mailbox matches, then the process is suspended and will be rescheduled for execution the next time a new message is put in the mailbox. Note that when a new message arrives, the messages in the save queue are not rematched; only the new message is matched.
- As soon as a message has been matched, then all messages that have been put into the save queue are reentered into the mailbox in the order in which they arrived at the process. If a timer was set, it is cleared.
- If the timer elapses when we are waiting for a message, then evaluate the expressions
ExpressionsTimeoutand put any saved messages back into the mailbox in the order in which they arrived at the process.
-
Book review: Erlang and OTP in Action

Title: Erlang and OTP in Action
Author: Martin Logan, Eric Merritt, and Richard Carlsson
Paperback: 432 pages
Publisher: Manning Publications; November 2010
Language: English
ISBN-10: 1933988789
ISBN-13: 978-1933988788
$38.99 (amazon.com)Overview
Even though this book has Erlang in its title, it’s only about 15% of the content dedicated to Erlang language itself — the biggest portion of the book is about OTP. Nowadays, when more and more developers get familiar with Erlang, they need a new book that can boost them to the next level of proficiency, where they can produce industry standard code leveraging all the power of Erlang platform. This book is supposed to fill this gap!
-
SpringOne2GX 2010
Last week I attended SpringOne2GX conference in Chicago, the main event in Spring/Groovy/Grails community. Here I want to post my brief review of this conference.
First impressions
The hotel (Westin Lombard) was nice and clean. Internet: there were 2 wireless networks and one cable — everything was free and worked pretty well, signal was good in almost all rooms. The conference reception was well organized — every participant received bunch of souvenirs and special edition of NFJS magazine. I saw hundreds of smiling and happy people of different ages and different outfits. Most of them with Macs. Most of them know each other. The food was fantastic, especially dinner with wine and beer.
Day 1
The first day was mostly introduction and orientation. There was only one talk on the schedule.
Rod Johnson — Keynote (video)
I thought Spring was initially created 7 years ago but the oldest class in the source tree is dated by January 17, 2001, so Spring is actually almost 10 years old. Because of the anniversary the main theme of the presentation was: Where Spring goes in the next decade.
Since the core framework is well crafted already, the focus will be on the integration and making Spring portfolio as a platform for applications. There are three key values in Spring — portability, productivity, and innovation — and the platform will be built along those dimensions.
Portability
In the past SpringSource made a good job by providing a framework that makes Java applications easily portable across different application servers. The goal for the next decade is to expand the same portability to the cloud — Google AppEngine, vFabric, vmforce, etc.
Productivity
As we all know the ultimate reason of the Spring existence is to make the life of application developer easier, our work is more productive. The framework hides the low-level boilerplate, and provides well defined abstractions. In the next year there will be several features added to the Spring portfolio. Rod mentioned some of them:
- Seamless GWT integration
- Database reverse engineering with roundtripping support in Spring Roo 1.1. You will be able to generate the domain object tree based on your database schema, and it will be updated every time you change the database.
- Spring Payment Services project with Visa integration.
Another aspect of productivity is a tool suite, where Spring provides STS. Rod invited Christian Dupuis on the stage, where he demoed how to developed Grails applications in STS. If you are a Grails developer you should definitely take a look at the latest version of STS — it will increase your productivity significantly.
Innovation
There will be several new projects released in the Spring portfolio soon:
- Spring Social — application abstraction for social networks.
- Spring Mobile — platform for multi-device applications.
- Spring-AMQP — API for integration with RabbitMQ.
- Spring Data — API to work with NoSQL databases, in particular Neo4J support in Spring Roo.
Keith Donald demoed GreenHouse project and corresponding iPhone app. This is a reference implementation of Spring Mobile and Spring Social, and this app was really really useful during the conference when I needed to check the schedule and find the room.
At the end of the presentation Rod introduced, and Mik Kersten demoed, the next big thing — Code2Cloud. It’s basically a tool that allows you to keep and manage your entire development environment in the cloud: the running app, the source code, the issue tracker, and the build server. Everything is in the cloud and configured by mouse click. It looks cool, and it definitely will be a buzz word in the next year, but I’m not sure if many people will use it. We’ll see.
Day 2
I’m going to write only about technical sessions I attended.
Jürgen Höller — What’s new in Spring Framework 3.1? (video)
That was one of the best talks of this conference: technical, right to the point, with well-wrtten slides, and personal charm of the presenter. Despite the number 3.1 in the title, Jürgen actually covered three versions of Spring framework: 3.0, 3.1, and 3.2. I’m going to briefly mention the interesting features, and if you want more details you can check the excellent on-line documentation.
Spring 3.0
-
Custom annotations. You can create your own annotation by combining multiple existing annotations in one group. Spring automatically detects your annotation during the application context startup, and no special configuration is required. This is a very handy feature, especially when you copy-paste the same annotation group over and over again.
-
Configuration classes and annotated factory methods. If you annotate a method with @Bean annotation Spring framework will make the output of the method a Spring bean. There are some other annotations supported, e.g. @Lazy.
-
Standardized annotations. Spring now supports JSR-330 @Inject, JSR-250 @ManagedBean, and EJB 3.x @TransactionAnnotation.
-
EL++. Expression language can be used now in bean definitions inside appcontext XML, and also in component annotations. Very powerful feature.
-
REST support. Spring provides RestTemplate for client code, @PathVariable annotation, and special view resolvers on the server side. It’s very interesting topic — check the documentation for details.
-
Declarative model validation. You can specify data constraints right in your code by using annotations — very similar to what you have in GORM.
-
Improved scheduling. New namespace, and @Scheduled and @Async annotations makes your appcontext smaller and more readable.
If you follow Spring releases, you probably use some or most of these features already. Now let’s see what Spring 3.1 brings to us.
Spring 3.1
-
Environment profiles for beans. Similar to Maven profiles but works in runtime. The idea here is to create a single deployment unit for all environments and enable certain Spring beans for specific environment. I can’t wait to try this feature in our enterprise project.
-
Cache abstraction. After 5 years of hibernation this feature is finally implemented. Spring provides an API to work with distributed cache, in particular in cloud environments. There will be adapters for most popular cache implementations, such as EhCache, GemFire, Coherence.
-
Conversation management, or how Jürgen calls it HttpSession++. It’s basically an extension of HttpSession shared across multiple browsers and window tabs. Looks very interesting.
-
Enhanced Groovy support.
-
c:namespace, which is a shortcut for<constructor-arg>, analogous top:namespace for properties. Small feature that makes your appcontext consistent and more readable.
Spring 3.2
Java SE 7 support, JDBC 4.1, support for fork-join framework, general focus on concurrent programming.
Jeff Brown — GORM inside and out
This talk was also good. I worked a bit with GORM before, and had an idea how it’s implemented, but it was useful to hear more details from one of its developers.
Jeff started with the background of GORM, the complexity of Hibernate and JPA, and how GORM solves this problem following convention-over-configuration and sensible defaults strategies. He showed how to model the domain objects, what happens behind the scene when you link objects together, how to specify uni- and bi-directional relationships, and how to change default collection implementation in case of one-to-many relationship.
During the presentation he was switching back and forth between sides and terminal, so it was easy to follow and understand the evolution of the sample application. He explained how to introduce various constraints into the model and how Grails would validate them. One of the interesting features I didn’t know about was how to test internationalized error messages. You don’t need to change your locale for that, simply add
lang=your_languageparameter to the URL, and Grails will switch to that language for all subsequent requests. Pretty handy.He concluded the talk by showing how dynamic finders are implemented in GORM using Groovy metaprogramming feature. Interesting part here is that you can implement similar things in your Groovy code using the same technique, basically having custom mini-GORM in your Groovy project!
Venkat Subramaniam — Improving your Groovy code quality
The title of this presentation was little bit misleading for me. I expected Venkat to show some Groovy specific mistakes and how to avoid them. Instead, he was talking about the errors that in most cases are equally applied to any programming language. He mentioned various code smells and explained how to fix them. If you are interested, you can download the slides from Venkat’s web site.
He also gave an advise how to maintain the high code quality:
- Have a respectable colleague review your code.
- Use code analysis tools like CodeNarc and Sonar Groovy plugin.
One of the topics he covered was the usage of the
returnkeyword in Groovy. That was interesting. Compare the following two functions, guess what they return, and check your answer in the consoledef func1() {try {5} finally {return 22}}def func2() {try {5} finally {22}}Paul King, Guillaume Laforge — Groovy.DSLs (from: beginner, to: expert) (video)
This would be very nice presentation if the speakers didn’t try to cover too much. This talk could be easily split into two: one is an overview of Groovy language and another one is DSL. Unfortunately they spent lot of time on theoretical DSL part and Groovy overview, so the practical DSL part was too short from my perspective. The good thing though is that I have slides now, so I can dig deeper into this subject at my spare time.
In the second part of the talk Paul and Guillaume explained which features of Groovy language make it so simple to create DSLs. Here are some of them:
- Static imports and import aliases.
- Simplified collection syntax.
- Small or no language noise.
- Aggregating multiple method calls using ‘with’ construct.
- Closures.
- Operator overloading.
- Metaprogramming.
In the last part speakers talked about different patterns and techniques of DSL implementations. They provided a comprehensive list of books you might want to read if you are interested in building DSLs.
Adrian Colyer — Technical keynote (video)
Adrian’s talk was mostly a reiteration of Rod’s keynote from the previous day with some technical details. He mentioned Spring Payment and Spring Data projects, bean profiles and cache support in the Spring core. He showed Spring portability in action by providing links to Spring applications deployed on Google AppEngine and vmForce.
Another interesting part was 20 minutes dedicated to RabbitMQ and Spring-AMQP. He even mentioned Spring-Erlang project which is supposed to be a convenient abstraction on top of standard Jinterface library.
As a continuation of innovation theme Graeme Rocher demoed GORM support for NoSQL databases. That was cool. He simply uninstalled Hibernate plugin and installed Redis plugin, without touching data model. Everything worked perfect. Right now Spring works with Redis and GemFire, but soon they are going to add support for CouchDB, Cassandra, Riak, Neo4j, and MongoDB. Another interesting thing Graeme showed was grails-console. It’s a pretty nice tool, you should check it out. It allows you to interact with the Grails data storage using GORM features. Very handy.
Another co-presenter was Keith Donald who demoed Spring Social and Spring Mobile. He explained how OAuth works, and how interoperability with social networks was implemented in GreenHouse.
The keynote was concluded by Jon Travis who demoed SpringInsight.
Day 3
Venkat Subramaniam — Functional programming in Groovy
That was an excellent talk and nice start of the new conference day. Venkat explained main concepts and values of functional programming, and illustrated the theory with comprehensible examples.
He compared imperative and functional style of programming by showing how to implement for-loop using
injectfunction in Groovy. I think it was one of the best explanations of functional folding I’ve ever heard. He also demonstrated map and filter operations usingcollectandfindAllmethods.He clarified the difference between function value and closure, and between iterative procedure and iterative process. He gave an example on how to pass closure as a parameter to simulate function object in Groovy. He also showed how to replace tail-recursion, which Groovy doesn’t support, with
injectmethod call.The presentation was concluded with an example of how to use functional techniques to build DSLs in Groovy.
Matthias Radestock, Mark Pollack, Mark Fisher — RabbitMQ and Spring-AMQP (video)
If you read my blog, you know that RabbitMQ is one of my latest interests. I decided to go to this talk just to see how the creators would present their projects. It turned out to be a nice introduction to both RabbitMQ and Spring-AMQP. They explained main concepts of AMQP and how it is different from JMS. Here I want to give you some ideas which were not obvious for me when I started working with RabbitMQ.
- Messaging is all about decoupling, and AMQP is much more flexible than JMS in terms of publisher-consumer decomposition.
- All resources are dynamically created and destroyed by clients — the static pre-configuration is optional.
- Exchanges are stateless, they don’t keep messages, they only copy and dispatch them. Queues hold the messages and deliver one message to a single client. They neither do routing nor message copying.
- Queue never receives the same message twice.
- If the message doesn’t match routing key it’s dropped.
- Because of the open protocol, you can use all available TCP tools to monitor your message traffic.
Besides AMQP implementation RabbitMQ also provides some other useful features like custom exchanges, exchange-to-exchange routing, different protocol adaptors, etc. Spring, as usual, gives you a consistent API on top of the RabbitMQ client which hides all low-level boilerplate and makes your application code more readable.
Craig Walls — Developing social-ready web applications (video)
This presentation was about integrating your Java code with different social networks. There are three types of such integration: widgets, embedded code, REST API. Craig briefly explained first two, and then dived into REST.
All popular social networks provide REST API which allows you to communicate with them. For simple operations, like search, you can just use standard Spring RestTemplate class to retrieve the data. Try for example the following URLs:
- http://api.twitter.com/1/friends/ids.xml?screen_name=ndpar
- http://search.twitter.com/search.json?q=s2gx
- https://graph.facebook.com/ndpar
This basic approach fails though if you try to post a new message, because you have to be authorized for update operations. That’s where OAuth comes in. The idea behind OAuth is pretty simple: instead of sharing your user-password with different clients, it uses generated tokens. This model is more flexible because if you want to revoke the permission from particular client you don’t need to change your password and notify rest of the clients — you just remove that client’s token from the list of authorized clients and that’s it. The only problem with OAuth and social networks is that they support different versions of OAuth. This problem is solved by Spring Social project.
Spring Social offers consistent template-based API across different social providers. It basically gives you an OAuth aware RestTemplate, so you can do something like this:
TwitterTemplate twitter = new TwitterTemplate(API_KEY, API_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRET);twitter.updateStatus("Hello #s2gx !");twitter.retweet(26887414177L);If you are in a social network business, definitely take a look at Spring Social.
Mark Pollack, Chris Richardson — Using Spring with non-relational databases (video)
Relational databases are great, right? They’ve been with us for ages. Everybody knows how to work with them, how to build SQL statements. Every language provides ODBC library. There are bunch of frameworks that make developer’s life easier. So why is so much buzz around NoSQL?
Mark and Chris started their talk highlighting some problems that exist in relational database world:
- Object-relational impedance mismatch. Complicated mapping of rich domain model to relational schema. Relational schema rigidity.
- Extremely difficult/impossible to scale write operations.
- Suboptimal performance in some cases.
All these issues are addressed in NoSQL databases. Although keep in mind that it’s not coming for free — you have to trade off ACID semantics, transactions and some other features of RDBMS. But if scalability is more important for you than consistency then NoSQL is your way to go.
There are tons of NoSQL databases available for you, but they all can be split into 4 categories based on their data model:
- Key-Value: Amazon Dynamo, Redis, Riak, Voldemort.
- Column: Google Bigtable, HBase, Cassandra.
- Document: CouchDB, MongoDB.
- Graph: Neo4j, Sones, InfiniteGraph.
Mark and Chris talked about each type, what their typical use cases are, and how their APIs look like. They showed examples for Redis, Cassandra, MongoDB, CouchDB and Neo4j. Then they introduced Spring Data project which, as everything from SpringSource, simplifies the application development and hides low-level code. Right now they support most of the popular NoSQL databases, and they plan to add more in the future.
The project is in active development phase, and the new contributors are welcome. So if it sounds interesting for you, go and check it out.
Day 4
Hans Dockter — Gradle — a better way to build
I never played with Gradle, so I was very curious to see how it looks like. According to Hans, who is the creator of this tool, Gradle is a general purpose build system with Groovy DSL interface. It’s written in Java and provides build-in support for Java, Groovy, Scala, web and OSGi projects. It’s a build language, so you can extend it for your own purposes if needed.
If you compare it with Ant, Gradle is definitely much better because it’s more compact and flexible. It offers dependency resolution with integration with Maven and Ivy repositories. It also has some advanced features like incremental builds for custom tasks and parallel testing.
The only problem I had with this presentation was that Hans kept comparing Gradle with Maven. In my opinion they are not comparable. They have different philosophy if you want. All Maven “constraints” are imposed by design, so it makes no sense to blame Maven for them. I think Ant-Gradle comparison is more appropriate and that’s what Hans should have emphasized.
Other than that the session was pretty informative, and I have a better picture of Gradle now.
Brian Sletten — Groovy + The Semantic Web
I had no idea what Semantic Web was. I saw this term first time on the conference schedule, so I decided to go to this talk just to educate myself. I cannot even briefly describe all the discoveries I made during this presentation because I still feel little bit overwhelmed. I just want to provide some links from Brian’s slides that can guide you if you want to learn this concept.
- Semantic Web — article from wikipedia.
- Formal W3C specs: RDF, RDFa, SKOS, SPARQL, OWL.
- SPARQL demo.
- RDFa distiller and parser. Try to feed Brian’s test page URL (http://bosatsu.net/nfjs/test.html) to the distiller and see what it returns.
- OG — open graph protocol.
- Jena — Java API to work with Semantic Web.
- Java-RDFa parser.
- Pellet — Java API for OWL.
Conclusion
Whew! This happened to be longer review than I planned initially. If you are still with me, congratulations!
There were much more presentations at this conference but because of the tight schedule I had to sacrifice 80% of them. My overall impression from this conference is very positive. If you are a Spring/Groovy/Grails developer I encourage you to go to this event next year. The biggest benefit of it: You start seeing the Spring as a universe, not as a bunch of separate projects. You cannot get this feeling from the documentation, even if it’s perfect as the Spring one.
-
Integrating RabbitMQ with ejabberd
ejabberd is integrated with RabbitMQ by means of mod_rabbitmq gateway. If you followed my ejabberd installation instructions, you should already have mod_rabbitmq installed.
Configure mod_rabbitmq
Open /opt/ejabberd/ejabberd/etc/ejabberd/ejabberd.cfg file, find modules section, and add mod_rabbitmq stanza to the list
/opt/ejabberd/ejabberd/etc/ejabberd/ejabberd.cfg {modules,[...{mod_rabbitmq, [{rabbitmq_node, RABBIT_NODE}]},...]}.You need to replace RABBIT_NODE with the real value, which you can find from the RabbitMQ process information
$ ps -ef | grep beam rabbitmq 8525 8142 0 16:37 pts/0 ... -sname rabbit@ubuntu ...You can see my RabbitMQ node name is rabbit@ubuntu.
Set up cookie
To make RabbitMQ and ejabberd work together, they have to run in the same Erlang cluster. That means they have to use the same cookie file. If you installed RabbitMQ from binary distribution, it uses the user’s cookie ~/.erlang.cookie. ejabberd, on the other hand, uses its own cookie. Let’s replace it with the user’s
$ cd /opt/ejabberd/ejabberd/var/lib/ejabberd $ rm -f .erlang.cookie $ ln -s ~/.erlang.cookieRestart ejabberd server
$ /opt/ejabberd/ejabberd/sbin/ejabberdctl restartAdd rabbit buddy to roster
The rabbit’s JID consists of two parts: exchange name and routing domain. The routing domain is a string
rabbitmq.EJABBERD_HOSTwhere EJABBERD_HOST is the host you registered in ejabberd.cfg. In my case the routing domain israbbitmq.jabber.ndpar.com.For the name you can use any exchange name available in the RabbitMQ server. I use
amq.fanoutexchange which exists in every RabbitMQ server. So I go to my IM client (Adium) and add this user to the buddies listamq.fanout@rabbitmq.jabber.ndpar.com.Rabbit’s greetings
To publish a message to RabbitMQ I use the same Groovy script as in the previous post
$ ./publisher.groovy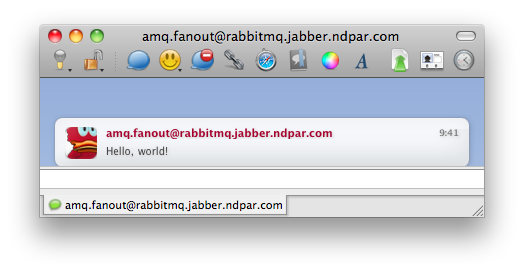
Resources
- Tony Garnock-Jones’ presentation slides about RabbitMQ and its extensions.
-
Get started with RabbitMQ
RabbitMQ is an open-source implementation of AMQP. If you don’t know what AMQP is, I encourage you to read about it on the official web site or the reference page. What I personally like in RabbitMQ/AMQP is
- AMQP is a free alternative to expensive TIBCO Randezvous.
- Functionality-wise AMQP is a superset of JMS.
- RabbitMQ is written in Erlang, which means fault-tolerance and reliability.
In this short blog entry I show how to install RabbitMQ on a *nix box, and verify that it’s working with a simple Groovy client.